今までLLMをローカル環境で動かすのは何か面倒くさそうで敬遠していたんだけど、やってみたらめちゃ簡単だったのでご紹介。なお本記事を参考にしてトラブルになっても一切責任は負えませんのでご了承ください。
LM Studioをインストールする
公式ホームページはこちら。LM Studio
なおググったら一番上に出てくる模様。
自分のOSに対応したものをダウンロードしてインストールする。
LM Studioを日本語化する(任意)
LM Studioを起動すると、最初にLLMをインストールしてみよう!みたいな案内が出るけど無視して良い(たぶん)。
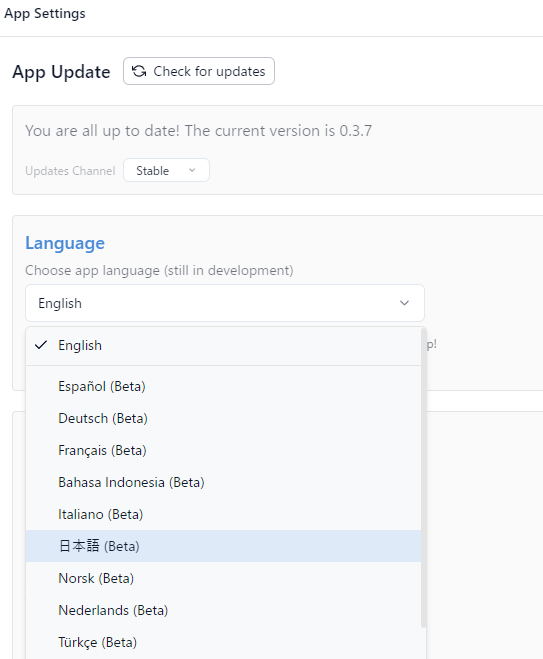
最初の画面に移行すると、右下に小さい歯車マークがあるので、
クリックすると設定画面に行ける。
で、言語のところを日本語にすればオーケー。
ランタイムをインストールする
最初の画面に戻って左上を見ると、
こんな感じになってると思うので、一番下の虫眼鏡マークをクリックする。
そうして左列の真ん中にあるランタイムをクリックすると、
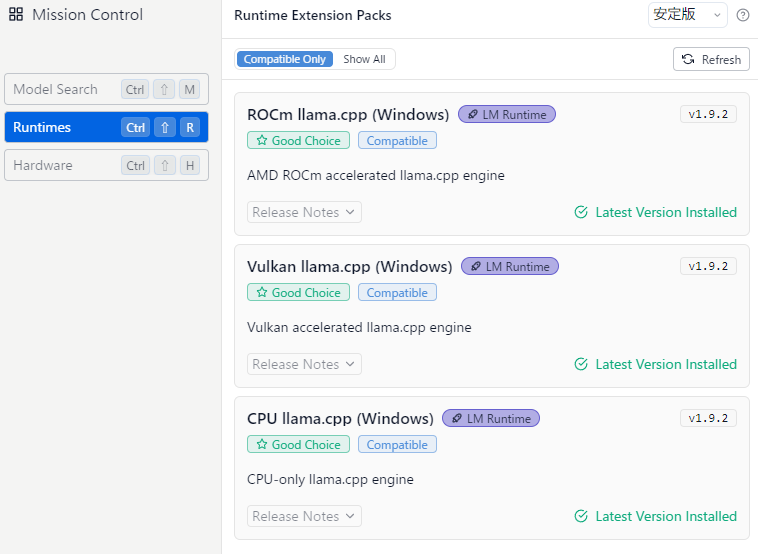
こんな感じで項目が出るので、全部インストールする(たぶん必要なものだけで良い、けど面倒だから全部)。
LLM(今回はdeepseek-r1)をダウンロードする
ランタイムの時と同じ画面で、今度は左列の項目からModel Searchをクリックして、検索ボックスにdeepseekと入力する。
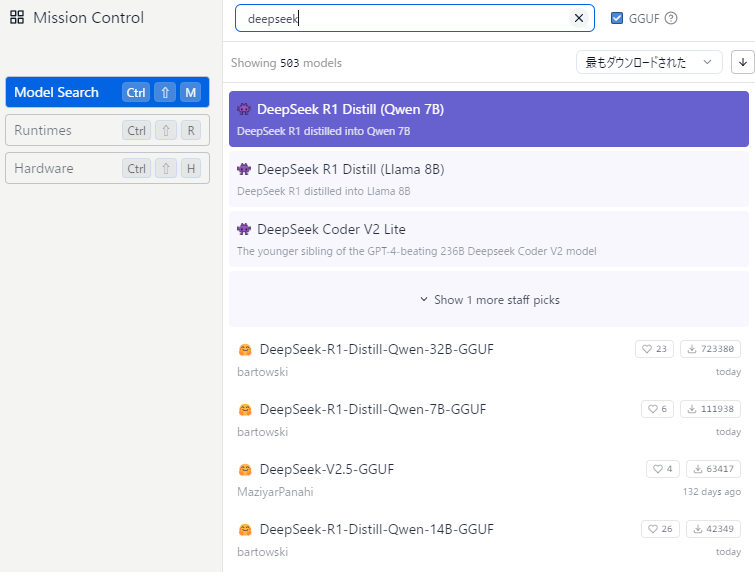
すると候補がいっぱい出てくる。
どれを使えばよいのという話だけれど、これはたぶん使っているgpuのvram容量によると思う。rtx4090みたいなつよつよgpuを使っているなら32Bが良いと思われる。僕は違うので(rx7600xt 16gb)Qwen-14Bにした。
deepseek-r1 14Bを適用する
あとは最初の画面に戻って、左列からチャットマークをクリックして、使いたいモデルを選べばよい。
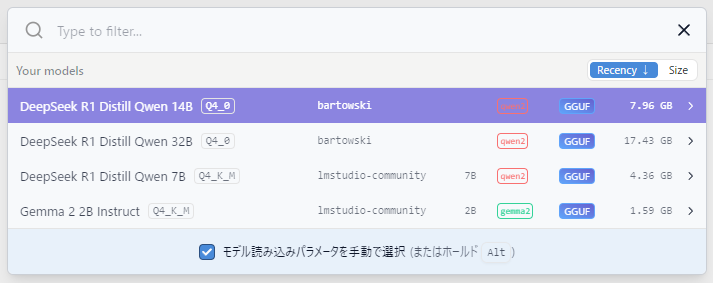
ただ選んだあと、
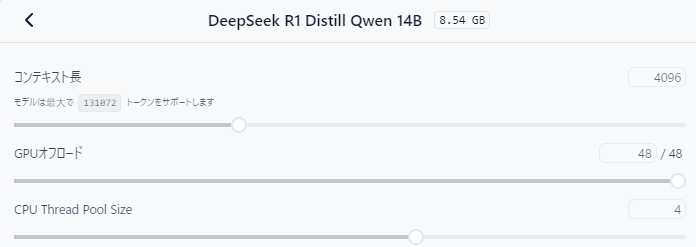
こんな感じでパラメータを設定できるのだけれど、可能ならGPUオフロードの項目を最大値にしたい。
これはどうやらLLMをどれくらいvram上で処理しますか、みたいな項目らしく、当然最大値にした方が処理は高速になる。
ただ32Bだとvram16gbでも足りず、動作は激遅だったので、泣く泣く14Bを使用したという次第。
そんな感じで設定したら、あとはプロンプトを入れて遊ぶだけ!
これは32Bで5分くらいかけて出力したおいしい卵焼きの作り方。

たのしい!
実際deepseek-r1 14Bは使えるか?
とまあこんな感じでゆるーく説明したわけだけれど、僕の環境(ryzen5600xとrx7600xt)だと14Bをギリ我慢できるくらいの速度で動作させるのが限界だった。その上deepseek-r1 14Bは日本語の入出力があまりうまくいかない印象で、どうにも使い勝手が悪い。
geminiとかgoogle ai studioとかのほうがレスポンスは遥かに高速だし、普段使いならこっちかなと一般人としては思った。
ただ一応ローカルでLLMを動かすのがどんな感じなのかは今回やってみてわかったので、次PCを買うときは気合を入れて末尾が90番のgpuを買う可能性も、まあないことはないのかもしれない。ただ何十万円もかけてローカルでLLMを使える環境を整える必要があるのかというと、うーん、どうなんだろう…
ということで今回は終わり!